JSON 파일 데이터베이스에서 PostgreSQL로: 서비스 시그니처를 유지하며 데이터 레이어 교체하기
`users.json`, `labels/*.json` 파일 저장소를 PostgreSQL로 교체하면서 라우트 9개는 한 줄도 수정하지 않았습니다. 계층 경계를 미리 뽑아 둔 지난 편 리팩토링의 보상을 그대로 보여 주는 실전 기록입니다.

1. 문제 상황: 파일 기반 저장소의 한계
앞선 Flask Blueprint 분해 편에서 1,932줄짜리 app.py를 라우트와 서비스로 나누었습니다. 그런데 서비스 레이어 안을 들여다보면, 여전히 JSON 파일을 직접 읽고 쓰는 코드가 남아 있었습니다.
# 리팩토링 직후 services/user_service.py (일부)
from utils.helpers import _load_json, _save_json
from config import USERS_FILE
def _get_users() -> dict:
users = _load_json(USERS_FILE, {})
# ... admin 기본 생성 로직
return users
def _save_users(users: dict):
_save_json(USERS_FILE, users)
모든 데이터가 data/ 아래 JSON 파일로 저장되고 있었습니다.
data/
├── users.json
├── classes/<user_id>.json
├── labels/<user_id>.json
├── activities/<user_id>.json
├── feedback/<user_id>.json
├── trainings/<train_id>.json
└── auto_models.json
이 구조가 주는 고통
| 문제 | 실제 증상 |
|---|---|
| 동시성 없음 | 두 사용자가 동시에 라벨을 저장하면 파일 덮어쓰기로 데이터 유실 위험 |
| 트랜잭션 없음 | 이미지 업로드 → 어노테이션 저장 중간에 실패하면 부분 상태가 남음 |
| 쿼리 불가 | "지난 7일간 활동이 많은 사용자" 같은 조건 조회가 전수 순회 |
| 인덱스 없음 | 사용자 수가 늘수록 JSON 파일 로드 + 파싱 비용 선형 증가 |
| 조인 없음 | 사용자별 이미지 수를 세려면 파일 여러 개를 교차로 읽어야 함 |
| 마이그레이션 부재 | 스키마가 바뀌면 수동으로 모든 JSON을 수정 |
이 프로젝트의 인수인계 로드맵에서 GitHub Issue #12번이 바로 이 교체 작업이었습니다. 목표는 명확했습니다.
라우트 파일은 단 한 줄도 수정하지 않고, 데이터 레이어만 PostgreSQL + SQLAlchemy로 교체한다.
2. 왜 "서비스 시그니처 유지"가 핵심인가
일반적인 DB 마이그레이션은 "JSON을 정리해서 스키마로 옮기고, 모델을 만들고, 라우트를 수정한다"는 흐름을 따릅니다. 하지만 이 프로젝트는 다른 접근이 필요했습니다. 이유는 단순합니다.
- 테스트가 없습니다. 검증은 수동 smoke test에 의존합니다.
- 42개 API 엔드포인트가 얽혀 있습니다. 라우트 내부 구조가 다양해 일괄 수정이 위험합니다.
- 프론트엔드 계약이 딕셔너리 형태의 사용자 객체(
{id, username, displayName, ...})에 이미 단단히 결합돼 있습니다.
그래서 전략을 거꾸로 잡았습니다.
서비스 모듈의 공개 함수 시그니처와 반환 포맷은 그대로 유지한 채, 내부 구현만 SQLAlchemy로 교체한다.
즉, _get_users()는 여전히 dict를 반환해야 하고, _get_user_by_id(uid)는 여전히 dict 또는 None을 반환해야 합니다. 라우트 입장에서는 아무것도 바뀌지 않은 것처럼 보여야 합니다.
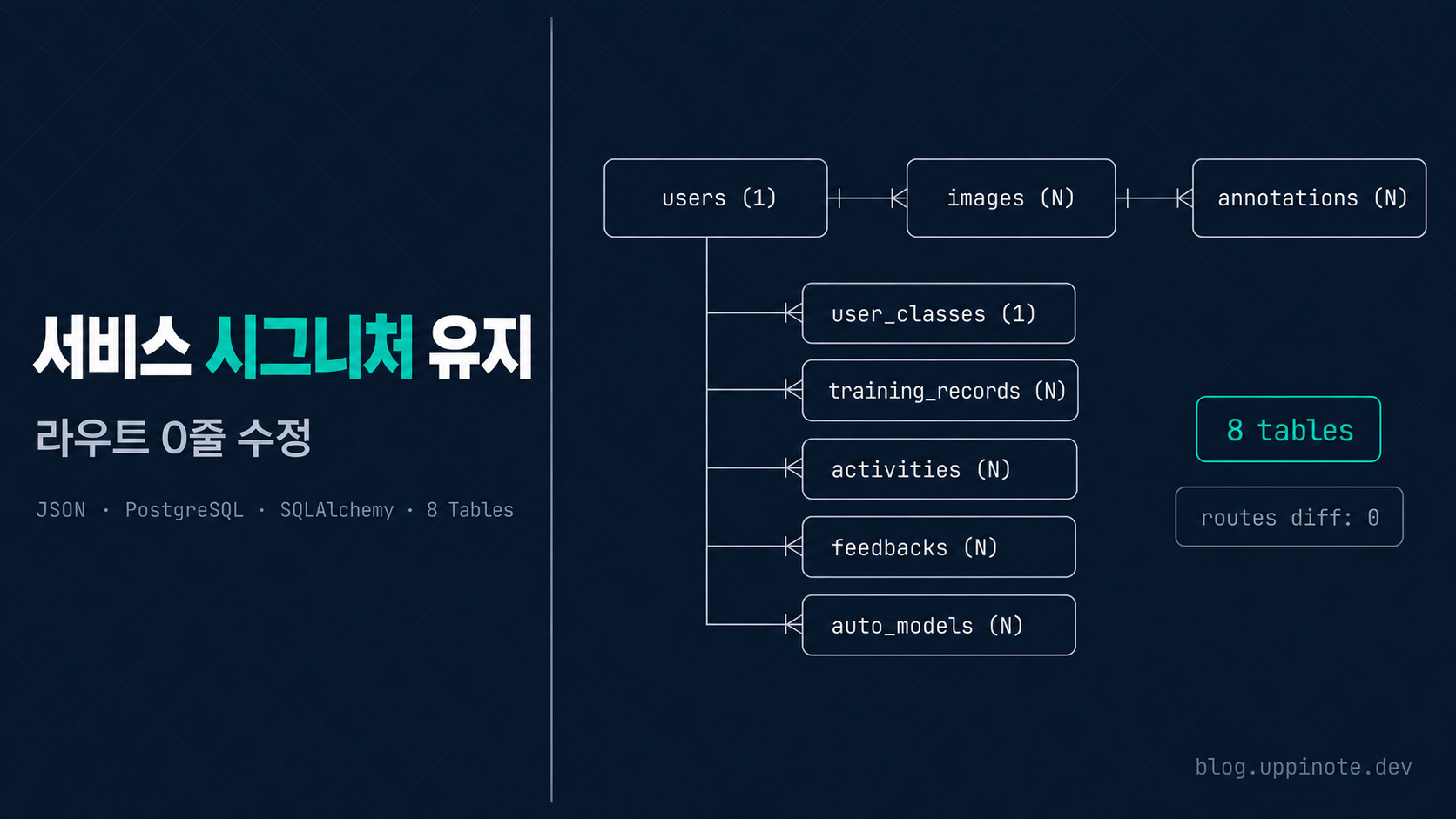
3. 8개 테이블 설계
먼저 JSON 파일 7종을 정규화된 8개 테이블로 매핑했습니다.
| JSON 파일 | 테이블 | 비고 |
|---|---|---|
users.json |
users |
기존 id/username 그대로 PK |
classes/<uid>.json |
user_classes |
사용자당 한 행, classes/class_colors JSON 컬럼 |
| 이미지 파일 시스템 메타 | images |
파일 → 행 1:1 매핑, user_id로 FK |
labels/<uid>.json의 어노테이션 배열 |
annotations |
이미지당 여러 행, image_id FK |
activities/<uid>.json |
activities |
사용자별 활동 로그 |
feedback/<uid>.json |
feedbacks |
피드백 |
trainings/<train_id>.json |
training_records |
학습 이력 |
auto_models.json |
auto_models |
자동 라벨링용 업로드 모델 |
관계도는 다음과 같습니다.
users (1) ─── (N) images ─── (N) annotations
│
├─── (1) user_classes
├─── (N) training_records
├─── (N) activities
├─── (N) feedbacks
└─── (N) auto_models
모든 "사용자 소유" 테이블은 ON DELETE CASCADE로 연결해 사용자 삭제 시 자동 정리되도록 했습니다. 이것도 JSON 시절에는 수동으로 파일을 지워야 했던 작업입니다.
4. SQLAlchemy 모델 작성
Flask-SQLAlchemy의 표준 패턴대로 각 모델을 별도 파일에 분리했습니다.
models/user.py
# models/user.py
from extensions import db
class User(db.Model):
__tablename__ = "users"
id = db.Column(db.String(36), primary_key=True)
username = db.Column(db.String(64), nullable=False, unique=True)
display_name = db.Column(db.String(128), nullable=False)
email = db.Column(db.String(256), default="")
password_hash = db.Column(db.String(512), nullable=False)
role = db.Column(db.String(16), nullable=False, default="user")
created_at = db.Column(db.DateTime(timezone=True), server_default=db.func.now())
last_login = db.Column(db.DateTime(timezone=True), nullable=True)
images = db.relationship(
"Image", backref="user", lazy="dynamic",
cascade="all, delete-orphan",
)
training_records = db.relationship(
"TrainingRecord", backref="user", lazy="dynamic",
cascade="all, delete-orphan",
)
activities = db.relationship(
"Activity", backref="user", lazy="dynamic",
cascade="all, delete-orphan",
)
feedbacks = db.relationship(
"Feedback", backref="user", lazy="dynamic",
cascade="all, delete-orphan",
)
auto_models = db.relationship(
"AutoModel", backref="user", lazy="dynamic",
cascade="all, delete-orphan",
)
models/image.py
# models/image.py
import uuid
from extensions import db
class Image(db.Model):
__tablename__ = "images"
id = db.Column(db.String(36), primary_key=True, default=lambda: str(uuid.uuid4()))
user_id = db.Column(
db.String(36),
db.ForeignKey("users.id", ondelete="CASCADE"),
nullable=False,
)
filename = db.Column(db.String(512), nullable=False)
file_size = db.Column(db.BigInteger, default=0)
labeled = db.Column(db.Boolean, default=False)
auto_labeled = db.Column(db.Boolean, default=False)
uploaded_at = db.Column(db.DateTime(timezone=True), server_default=db.func.now())
label_saved_at = db.Column(db.DateTime(timezone=True), nullable=True)
annotations = db.relationship(
"Annotation", backref="image", lazy="dynamic",
cascade="all, delete-orphan",
)
__table_args__ = (
db.UniqueConstraint("user_id", "filename", name="uq_user_filename"),
)
사용자 한 명이 같은 파일명을 중복 업로드할 수 없도록 UniqueConstraint도 걸었습니다. JSON 시절에는 애플리케이션 로직으로 중복 체크를 했었는데, DB 제약이 더 안전하고 빠릅니다.
models/annotation.py
# models/annotation.py
from extensions import db
class Annotation(db.Model):
__tablename__ = "annotations"
id = db.Column(db.String(36), primary_key=True)
image_id = db.Column(
db.String(36),
db.ForeignKey("images.id", ondelete="CASCADE"),
nullable=False,
)
type = db.Column(db.String(16), default="bbox") # bbox | polygon | classification
class_name = db.Column(db.String(128), nullable=False)
x = db.Column(db.Float, default=0)
y = db.Column(db.Float, default=0)
w = db.Column(db.Float, default=0)
h = db.Column(db.Float, default=0)
confidence = db.Column(db.Float, nullable=True)
is_auto = db.Column(db.Boolean, default=False)
train_id = db.Column(db.String(36), nullable=True)
extra = db.Column(db.JSON, nullable=True) # polygon 좌표, 보조 점수 등
created_at = db.Column(db.DateTime(timezone=True), server_default=db.func.now())
여기서 주목할 점은 extra = db.Column(db.JSON, ...)입니다. PostgreSQL 16의 JSONB를 활용해 정형 컬럼으로 수용하기 어려운 필드(segmentation의 polygon 좌표, classification의 보조 점수 allScores 등)를 유연하게 담았습니다. 정규화 원칙을 지키면서도 도메인 확장에 유연한 타협점입니다.
models/__init__.py
# models/__init__.py
from extensions import db
from models.user import User
from models.image import Image
from models.annotation import Annotation
from models.user_class import UserClass
from models.training_record import TrainingRecord
from models.activity import Activity
from models.feedback import Feedback
from models.auto_model import AutoModel
__all__ = [
"db", "User", "Image", "Annotation", "UserClass",
"TrainingRecord", "Activity", "Feedback", "AutoModel",
]
모든 모델을 한곳에서 노출해 서비스 모듈에서 from models import User로 깔끔하게 import 하게 만들었습니다.
5. extensions.py에 db 정착
지난 편에서 extensions.py를 "확장이 모이는 곳"이라고 설계했던 것이 여기서 보상받습니다.
Before: CORS만 있던 시절
# extensions.py (Blueprint 분해 직후)
from flask_cors import CORS
def init_extensions(app):
CORS(app, supports_credentials=True, origins=app.config.get("ALLOWED_ORIGINS", ["*"]))
After: db 합류
# extensions.py (PostgreSQL 전환 후)
from flask_cors import CORS
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
def init_extensions(app):
CORS(app, supports_credentials=True, origins=app.config.get("ALLOWED_ORIGINS", ["*"]))
if app.config.get("SQLALCHEMY_DATABASE_URI"):
db.init_app(app)
핵심은 두 가지입니다.
db가 모듈 레벨에 있어야 모델 파일에서from extensions import db로 참조할 수 있습니다. 순환 import를 피하면서 Flask-SQLAlchemy의 전역 인스턴스 패턴을 깨끗하게 구현하는 표준적인 방법입니다.SQLALCHEMY_DATABASE_URI가 설정된 경우에만db.init_app(app)을 호출합니다. DB 없이 실행해야 하는 테스트/CLI 환경에서도 앱이 부팅할 수 있게 한 안전장치입니다.
create_app() 팩토리 자체는 하나도 바뀌지 않았습니다. init_extensions(app)만 호출하면 CORS와 DB가 같이 초기화됩니다. 이것도 지난 편 리팩토링의 보상입니다.
6. 서비스 레이어 내부 교체
이제 하이라이트입니다. 라우트 파일이 기대하는 함수 시그니처와 반환 포맷을 그대로 유지한 채, 내부를 SQLAlchemy로 교체합니다.
Before: JSON 기반
# services/user_service.py (Before)
from config import USERS_FILE
from utils.helpers import _load_json, _save_json, _now
def _get_users() -> dict:
users = _load_json(USERS_FILE, {})
if not users:
admin_pw = os.environ.get("ADMIN_PASSWORD", "admin1234")
users["admin"] = {
"id": "admin", "username": "admin",
"displayName": "관리자",
"password": _hash_password(admin_pw),
"role": "admin", "createdAt": _now(), "lastLogin": "",
}
_save_json(USERS_FILE, users)
return users
def _save_users(users: dict):
_save_json(USERS_FILE, users)
def _get_user_by_id(uid: str):
return _get_users().get(uid)
After: SQLAlchemy 기반
# services/user_service.py (After)
from datetime import datetime
from extensions import db
from models import User
from utils.helpers import logger
def _user_to_dict(u: User) -> dict:
"""SQLAlchemy User 객체를 라우트가 기대하는 dict 형식으로 변환"""
return {
"id": u.id,
"username": u.username,
"displayName": u.display_name,
"email": u.email or "",
"password": u.password_hash,
"role": u.role,
"createdAt": u.created_at.isoformat() if u.created_at else "",
"lastLogin": u.last_login.isoformat() if u.last_login else "",
}
def _get_users() -> dict:
users_list = User.query.all()
if not users_list:
admin_pw = os.environ.get("ADMIN_PASSWORD", "admin1234")
if not os.environ.get("ADMIN_PASSWORD"):
logger.warning(
"ADMIN_PASSWORD 미설정 — 기본 비밀번호(admin1234) 사용 중."
)
admin = User(
id="admin",
username="admin",
display_name="관리자",
email="[email protected]",
password_hash=_hash_password(admin_pw),
role="admin",
)
db.session.add(admin)
db.session.commit()
users_list = [admin]
return {u.id: _user_to_dict(u) for u in users_list}
def _save_users(users: dict):
"""DB 기반이므로 라우트 호환을 위해 dict 전체를 받아 각 사용자를 업서트"""
for uid, data in users.items():
user = db.session.get(User, uid)
if user is None:
user = User(
id=uid,
username=data["username"],
display_name=data["displayName"],
email=data.get("email", ""),
password_hash=data["password"],
role=data.get("role", "user"),
)
db.session.add(user)
else:
user.username = data["username"]
user.display_name = data["displayName"]
user.email = data.get("email", "")
user.password_hash = data["password"]
user.role = data.get("role", user.role)
if data.get("lastLogin"):
try:
user.last_login = datetime.fromisoformat(data["lastLogin"])
except (ValueError, TypeError):
pass
# DB에 있지만 dict에 없는 사용자는 삭제 (관리자 삭제 처리)
existing_ids = {u.id for u in User.query.all()}
for uid in existing_ids - set(users.keys()):
user = db.session.get(User, uid)
if user:
db.session.delete(user)
db.session.commit()
def _get_user_by_id(uid: str):
user = db.session.get(User, uid)
return _user_to_dict(user) if user else None
주목할 세 가지 설계 선택
① _user_to_dict 변환 헬퍼
라우트가 기대하는 키(displayName, createdAt, lastLogin)는 camelCase이고, SQLAlchemy 모델은 snake_case(display_name, created_at, last_login)입니다. 이 변환을 한 곳에 모아 라우트가 볼 때 "Before와 동일한 dict"를 반환합니다. JSON 필드명을 그대로 프론트엔드 계약으로 유지하기 위한 얇은 어댑터입니다.
② _save_users(dict)의 역변환
원래 _save_users(users)는 dict 전체를 받아 JSON 파일을 덮어쓰는 계약이었습니다. 이 계약을 유지하려면, dict를 받아 DB에 업서트(UPSERT) 해야 합니다. dict에 없는 사용자는 삭제까지 처리합니다. 계약 보존을 위해 효율성을 일부 포기한 타협입니다. 장기적으로는 _create_user, _update_user, _delete_user로 라우트를 리팩토링하는 것이 맞지만, 이번 단계의 목표는 "라우트 변경 없이 DB로 이행"이었기에 의도적으로 이 형태를 유지했습니다.
③ 구 JSON 계정 호환
기존 JSON에 저장돼 있던 사용자 데이터를 잃지 않기 위해, 구형 SHA-256 해시로 저장된 비밀번호도 여전히 검증 가능합니다(해시 로직은 지난 편 그대로입니다). 마이그레이션 이후 첫 로그인 성공 시점에 PBKDF2로 자동 업그레이드됩니다.
7. 학습 스레드에서 app context 다루기
가장 까다로웠던 부분은 백그라운드 학습 스레드에서 DB를 만지는 경우였습니다. Flask-SQLAlchemy는 요청 컨텍스트 밖에서 db.session을 쓰면 "Working outside of application context" 에러를 발생시킵니다.
# services/training_service.py (After, 일부)
from flask import current_app
from extensions import db
from models import TrainingRecord
def _get_app():
"""백그라운드 스레드에서도 안전하게 Flask 앱 인스턴스를 얻는다."""
try:
return current_app._get_current_object()
except RuntimeError:
# 워커 프로세스: create_app()을 새로 호출해 새 앱을 구성
from app import create_app
return create_app()
def _save_training_record(train_id: str, patch: dict):
app = _get_app()
with app.app_context():
record = db.session.get(TrainingRecord, train_id)
if record is None:
record = TrainingRecord(id=train_id, **patch)
db.session.add(record)
else:
for key, value in patch.items():
setattr(record, key, value)
db.session.commit()
두 가지 경우를 모두 처리합니다.
- 현재 스레드에 app context가 있는 경우:
current_app._get_current_object()로 실제 앱을 얻어app_context()로 감쌉니다. - 완전히 분리된 워커 프로세스의 경우:
create_app()으로 독립 앱을 새로 만들어 쓰고, 그 위에서app_context()를 엽니다.
이 패턴은 다음 편에서 다룰 ProcessPoolExecutor 전환과도 맞물립니다.
8. Docker Compose로 PostgreSQL 준비
개발자가 한 명일 때 가장 편한 방법은 Docker Compose입니다.
# docker-compose.yml
services:
db:
image: postgres:16-alpine
environment:
POSTGRES_DB: labelplatform
POSTGRES_USER: labelplatform
POSTGRES_PASSWORD: labelplatform_dev
ports:
- "5432:5432"
volumes:
- pgdata:/var/lib/postgresql/data
volumes:
pgdata:
docker compose up -d 한 줄로 PostgreSQL 16이 뜨고, 애플리케이션은 DATABASE_URL로 접속합니다. .env.example에 필수 항목을 추가했습니다.
# .env.example
SECRET_KEY=change-me
ALLOWED_ORIGINS=http://localhost:8080
DATABASE_URL=postgresql://labelplatform:labelplatform_dev@localhost:5432/labelplatform
config.py에는 이 URL을 읽어 Flask-SQLAlchemy 설정으로 전달하는 라인을 추가했습니다.
# config.py (추가)
class Config:
...
SQLALCHEMY_DATABASE_URI = os.environ.get("DATABASE_URL")
SQLALCHEMY_TRACK_MODIFICATIONS = False
9. Alembic 마이그레이션 설정
스키마 변경 이력을 관리하기 위해 Alembic을 추가했습니다.
; alembic.ini (요약)
[alembic]
script_location = migrations
sqlalchemy.url = postgresql://labelplatform:labelplatform_dev@localhost:5432/labelplatform
# migrations/env.py (일부)
from app import create_app
from extensions import db
import models # 모든 모델 로드 (side-effect import)
app = create_app()
target_metadata = db.metadata
def run_migrations_online():
with app.app_context():
with db.engine.connect() as connection:
context.configure(
connection=connection,
target_metadata=target_metadata,
)
with context.begin_transaction():
context.run_migrations()
핵심은 import models입니다. Alembic의 autogenerate가 db.metadata에서 테이블 정의를 가져오려면, 모델 파일이 임포트되어 메타데이터에 등록된 상태여야 합니다. models/__init__.py를 통해 모두 로드되므로 한 줄이면 충분합니다.
10. JSON → PG 일괄 이관 스크립트
기존 JSON 데이터를 잃지 않고 옮기기 위해 별도 스크립트를 만들었습니다.
# scripts/migrate_json_to_pg.py (일부)
"""JSON → PostgreSQL 마이그레이션 스크립트"""
import os
import sys
sys.path.insert(0, os.path.dirname(os.path.dirname(__file__)))
from app import create_app
from extensions import db
from models import (
User, Image, Annotation, UserClass,
TrainingRecord, Activity, Feedback, AutoModel,
)
from config import (
USERS_FILE, ACTIVITY_DIR, LABELS_DIR, FEEDBACK_DIR,
TRAIN_DIR, CLASSES_DIR, AUTO_MODELS_FILE, UPLOAD_DIR,
)
from utils.helpers import _load_json, logger
def migrate():
app = create_app()
with app.app_context():
db.create_all()
logger.info("Tables created.")
# Phase A: Users
users_data = _load_json(USERS_FILE, {})
for uid, u in users_data.items():
if not db.session.get(User, uid):
db.session.add(User(
id=uid,
username=u.get("username", uid),
display_name=u.get("displayName", uid),
email=u.get("email", ""),
password_hash=u.get("password", ""),
role=u.get("role", "user"),
))
db.session.commit()
logger.info(f"Users migrated: {len(users_data)}")
# Phase B: User Classes
if CLASSES_DIR.exists():
for f in CLASSES_DIR.glob("*.json"):
uid = f.stem
data = _load_json(f, {})
if not db.session.get(UserClass, uid):
db.session.add(UserClass(
user_id=uid,
classes=data.get("classes", []),
class_colors=data.get("classColors", {}),
))
db.session.commit()
# Phase C: Images + Annotations (사용자별 순회)
for uid in users_data:
user_upload_dir = UPLOAD_DIR / uid
if not user_upload_dir.exists():
continue
labels_data = _load_json(LABELS_DIR / f"{uid}.json", {})
for img_file in sorted(user_upload_dir.iterdir()):
if not img_file.is_file():
continue
# ... 이미지 + 어노테이션 삽입
db.session.commit()
# Phase D, E, F: Activities, Feedbacks, TrainingRecords, AutoModels
...
if __name__ == "__main__":
migrate()
Phase 단위로 나눈 이유가 있습니다. 각 Phase가 독립적으로 commit 되어, 중간에 실패해도 앞 단계는 살아남습니다. Users가 먼저 들어가야 Images가 FK를 만족시킬 수 있고, Images가 있어야 Annotations가 들어갈 수 있습니다. 이 순서는 테이블 관계의 위상 정렬과 정확히 일치합니다.
11. 라우트 파일은 한 줄도 바뀌지 않았다
글 초반에 내세운 목표를 기억하시나요? "라우트는 한 줄도 수정하지 않는다." 실제로 그게 가능했는지 검증해 보겠습니다.
# Before 커밋과 After 커밋 사이 routes/ 폴더의 변경
$ git diff 6ed1c4f^ 6ed1c4f -- routes/ | wc -l
0
routes/ 폴더는 단 한 줄도 바뀌지 않았습니다. 전체 diff가 +1,052 / −96이었지만, 그 변화는 전부 models/, services/, migrations/, scripts/, extensions.py, config.py, docker-compose.yml에 집중됐습니다.
이것이 지난 편에서 "서비스 레이어를 먼저 뽑아야 한다"고 강조한 이유였습니다. 계층 경계가 명확하면, 한 계층의 구현 전체를 바꿔도 다른 계층이 흔들리지 않습니다.
12. 핵심 개념 정리
| 개념 | 이 프로젝트에서의 역할 |
|---|---|
| 서비스 시그니처 유지 | 라우트 호출부와 반환 포맷 불변 → 라우트 수정 0건 |
| Flask-SQLAlchemy 전역 db | extensions.py에 db = SQLAlchemy() 두고 모델/서비스에서 import |
_user_to_dict 어댑터 |
camelCase ↔ snake_case 컬럼명 변환을 한 곳에 집중 |
db.JSON 컬럼 |
polygon/classification 같은 확장 필드를 정규화 부담 없이 수용 |
| app context 래핑 | 백그라운드 스레드/프로세스에서 db.session 안전하게 사용 |
| Alembic autogenerate | target_metadata = db.metadata로 스키마 변경 추적 |
| Phase 단위 마이그레이션 | FK 의존 순서에 맞춰 이관, 부분 실패 복구 가능 |
13. 베스트 프랙티스 체크리스트
- [ ] 데이터 레이어 교체 전 서비스/라우트 경계가 분리되어 있나요?
- [ ] 서비스 모듈의 공개 함수 시그니처와 반환 포맷을 문서화했나요?
- [ ] 모델 컬럼명과 프론트엔드 계약 키명이 다르면 변환 어댑터를 두었나요?
- [ ] 외부 관계(
ForeignKey)에ondelete="CASCADE"가 필요한지 검토했나요? - [ ]
UniqueConstraint등 DB 제약으로 애플리케이션 로직을 대체할 수 있는 부분이 있나요? - [ ] Alembic
env.py에서 모든 모델이 로드되도록import models를 넣었나요? - [ ] 백그라운드 작업에서
db.session쓰는 경로를with app.app_context()로 감쌌나요? - [ ] JSON → DB 이관 스크립트가 Phase 단위로 commit 하도록 나누어져 있나요?
14. FAQ
Q1. _save_users(dict)의 UPSERT가 비효율적이지 않나요? 그냥 _create_user, _update_user로 API를 바꾸는 게 낫지 않나요?
A. 장기적으로는 그렇습니다. 이번 단계의 목적은 "데이터 레이어 교체"이고, 라우트와 프론트엔드 계약을 건드리지 않는 것이 제약 조건이었습니다. 서비스 API를 바꾸면 라우트 9개를 다시 열어야 하고 검증 비용이 수배로 늘어납니다. 지금은 "호환성을 유지하는 어댑터"로 취급하고, 다음 리팩토링 단계에서 라우트를 쪼갤 때 함께 정리하는 것이 안전합니다.
Q2. 모든 PK를 String(36)으로 정한 이유는?
A. 기존 JSON 데이터의 사용자 id가 uuid4()[:8] 같은 짧은 문자열이었기 때문입니다. 마이그레이션 시점의 호환을 위해 String(36)(UUID 문자열 최대 길이)으로 통일했습니다. 신규로 생성되는 이미지/어노테이션 id는 default=lambda: str(uuid.uuid4())로 완전 UUID를 사용합니다. 장기적으로는 id 체계를 일원화하는 후속 작업이 필요합니다.
Q3. JSONB가 아니라 db.JSON을 쓴 이유는?
A. SQLAlchemy의 db.JSON은 PostgreSQL에서 자동으로 JSONB로 매핑됩니다(바인더 레벨). 명시적으로 JSONB를 import 해도 되지만, db.JSON을 쓰면 다른 DB 드라이버에서도 동작하는 이점이 있습니다. 이 프로젝트는 PostgreSQL 전용이라 어느 쪽이든 차이가 없어 표준 형태를 선택했습니다.
Q4. Alembic 대신 db.create_all()만 쓰면 안 되나요?
A. 초기 배포는 가능하지만, 이후 스키마 변경 이력 추적과 롤백이 불가능합니다. 팀이 한 명이어도 "어느 시점에 어떤 컬럼이 추가됐는지"를 git history와 별개로 DB 내부에서 추적할 수 있어야 합니다. Alembic은 이 정보를 alembic_version 테이블로 관리합니다. 이후 편에서 db.create_all()과 Alembic의 관계 정리 커밋(b5aa38b)도 다룰 예정입니다.
Q5. 학습 스레드에서 current_app._get_current_object()를 쓰는 이유는?
A. current_app은 context-local 프록시이고, 스레드 경계를 넘으면 사라집니다. 백그라운드 스레드/프로세스는 "현재 앱"이라는 개념이 없습니다. 그래서 스레드 시작 전에 _get_current_object()로 실제 앱 객체를 꺼내 두거나, 완전히 분리된 프로세스에서는 create_app()으로 새 앱을 만들어 씁니다. 이 부분은 다음 편(ProcessPoolExecutor 전환)에서 더 깊이 다룹니다.
15. 참고 자료
- Flask-SQLAlchemy 공식 문서: 검색 키워드
flask-sqlalchemy quickstart - SQLAlchemy 2.x 공식 문서: 검색 키워드
sqlalchemy orm tutorial - Alembic Autogenerate: 검색 키워드
alembic autogenerate metadata - PostgreSQL JSONB 성능 가이드: 검색 키워드
postgresql jsonb index gin
16. 다음 단계
서비스 레이어가 SQLAlchemy로 넘어오면서 한 가지 새로운 문제가 드러났습니다. 학습을 백그라운드로 돌리는 기존 threading.Thread 방식은 DB 세션을 제대로 다루지 못했고, 서버 재시작 시 "running" 상태로 고아가 된 학습 기록이 생겼습니다. 다음 편에서는 이 문제를 ProcessPoolExecutor 전환으로 해결하는 과정을 다룹니다. max_workers=2로 동시 학습을 제한하고, PID 기반 SIGTERM 취소, 서버 시작 시 orphan 복구까지 함께 살펴봅니다.
🐍 Flask 백엔드 실전 시리즈 (9부작)
- 모놀리식 app.py를 Blueprint로 분해하기
- JSON 파일 DB에서 PostgreSQL로 마이그레이션 (현재 글)
- ML 학습 백그라운드 실행: ProcessPoolExecutor
- Python/SQLAlchemy N+1 쿼리 잡기
- train과 val이 같은 폴더일 때의 조용한 ML 버그
- 하나의 백엔드로 Detection/Classification/Segmentation
- Fail-fast 설정 검증과 Path Traversal 방어
- Rate Limiting을 걷어낸 날: 폐쇄망 보안
- 작지만 기억할 만한 네 가지 교훈