Flask에서 ML 학습 백그라운드 실행: threading의 한계와 ProcessPoolExecutor 전환
Flask에서 YOLO 학습을 `threading.Thread`로 돌리면 GIL 병목, 취소 불가, orphan 기록 세 문제가 생깁니다. `ProcessPoolExecutor`로 전환하면서 PID 기반 SIGTERM 폴백과 서버 기동 시 복구 훅까지 함께 다룹니다.

1. 문제 상황: threading으로 YOLO 학습 돌리기
지난 두 편에서 Flask 앱을 Blueprint로 쪼개고(1편) JSON 저장소를 PostgreSQL로 교체했습니다(2편). 이제 남은 구조적 부채 중 가장 큰 것 하나가 백그라운드 학습 실행 이었습니다.
기존 구현은 threading.Thread였습니다.
# 기존 방식 (Before)
import threading
def api_train_start():
# ... 학습 파라미터 파싱
t = threading.Thread(
target=run_yolo_train,
args=(uid, train_id, labeled_imgs, model_name, epochs, batch, img_size),
daemon=True,
)
t.start()
return jsonify({"ok": True, "trainId": train_id})
"백그라운드 실행"이라는 목적은 달성했지만, 이 구조는 세 가지 고질병을 동시에 앓고 있었습니다.
고질병 세 가지
| 문제 | 구체 증상 |
|---|---|
| GIL 병목 | YOLO 학습은 Python 레벨에서도 상당한 CPU를 쓰는데, 같은 인터프리터에서 Flask 요청도 처리됨. 학습 중 API 응답이 느려짐 |
| 취소 불가 | threading.Thread에는 안전한 취소 API가 없음. 사용자가 "학습 중단" 버튼을 눌러도 서버는 그냥 무시 |
| Orphan 학습 기록 | 학습 진행 중 서버가 재시작되면, DB에는 status="running"인 기록이 영원히 남음. 프론트엔드는 끝나지 않는 진행 바를 보여줌 |
여기에 더해, 2편에서 PostgreSQL로 넘어가면서 새로운 문제가 하나 더 드러났습니다. 학습 스레드에서 db.session을 쓰려면 Flask app context가 필요한데, 스레드 경계를 넘으면서 이 컨텍스트가 사라져 "Working outside of application context" 에러가 튀어나왔습니다.
2. 왜 ProcessPoolExecutor인가
파이썬에서 CPU를 쓰는 백그라운드 작업을 다룰 때 선택지는 몇 가지가 있습니다.
threading.Thread— GIL 때문에 CPU 작업은 병렬화되지 않음. I/O 위주 작업에만 적합.multiprocessing.Process— 프로세스 단위라 GIL을 우회. 하지만 수명 관리를 직접 해야 함.concurrent.futures.ThreadPoolExecutor— threading의 풀 래퍼. GIL 문제 동일.concurrent.futures.ProcessPoolExecutor— 프로세스 풀 래퍼. 제한된 워커 수, Future 추상화, 자동 수명 관리를 모두 제공.- Celery, RQ 같은 별도 큐 시스템 — 정식이지만 Redis/브로커 인프라 필요.
이 프로젝트는 폐쇄망 배포가 전제라 별도 인프라 없이 해결해야 했습니다. 그리고 GIL 우회와 동시성 제한이 둘 다 필요했기 때문에, ProcessPoolExecutor가 가장 적합했습니다.
# 전환 후 (After)
from concurrent.futures import ProcessPoolExecutor, Future
_executor = ProcessPoolExecutor(max_workers=2) # 동시 학습 2건 제한
_active_futures: dict[str, Future] = {}
def submit_training(uid, train_id, labeled_imgs, model_name, epochs, batch, img_size):
future = _executor.submit(
run_yolo_train,
uid, train_id, labeled_imgs, model_name, epochs, batch, img_size,
)
_active_futures[train_id] = future
def _on_done(f):
_active_futures.pop(train_id, None)
future.add_done_callback(_on_done)
return future
max_workers=2는 의도적 제약입니다. YOLO 학습 한 건이 GPU나 CPU를 크게 점유하므로, 동시에 너무 많이 돌면 전체 서버가 느려집니다. 풀 크기 제한으로 "queued" 상태를 자연스럽게 만들어 과부하를 예방합니다.
3. Future 추적: _active_futures 딕셔너리
ProcessPoolExecutor.submit()은 Future 객체를 반환합니다. 이 객체는 "작업이 끝났는가", "예외가 났는가" 같은 상태를 조회할 수 있고, 조건부 취소도 가능합니다. 다만 한 가지 한계가 있습니다. Future는 풀 외부에서 train_id로 직접 찾을 수 없습니다.
그래서 _active_futures: dict[str, Future]라는 모듈 레벨 매핑을 두고, 학습 시작 시점에 Future를 등록합니다.
_active_futures: dict[str, Future] = {}
def submit_training(uid, train_id, ...):
future = _executor.submit(run_yolo_train, ...)
_active_futures[train_id] = future
def _on_done(f):
_active_futures.pop(train_id, None) # ← 자동 정리
future.add_done_callback(_on_done)
return future
add_done_callback은 Future가 완료(성공/실패/취소)될 때 호출되는 후킹 지점입니다. 여기서 _active_futures에서 해당 train_id를 제거해, 딕셔너리가 무한히 커지지 않도록 했습니다.
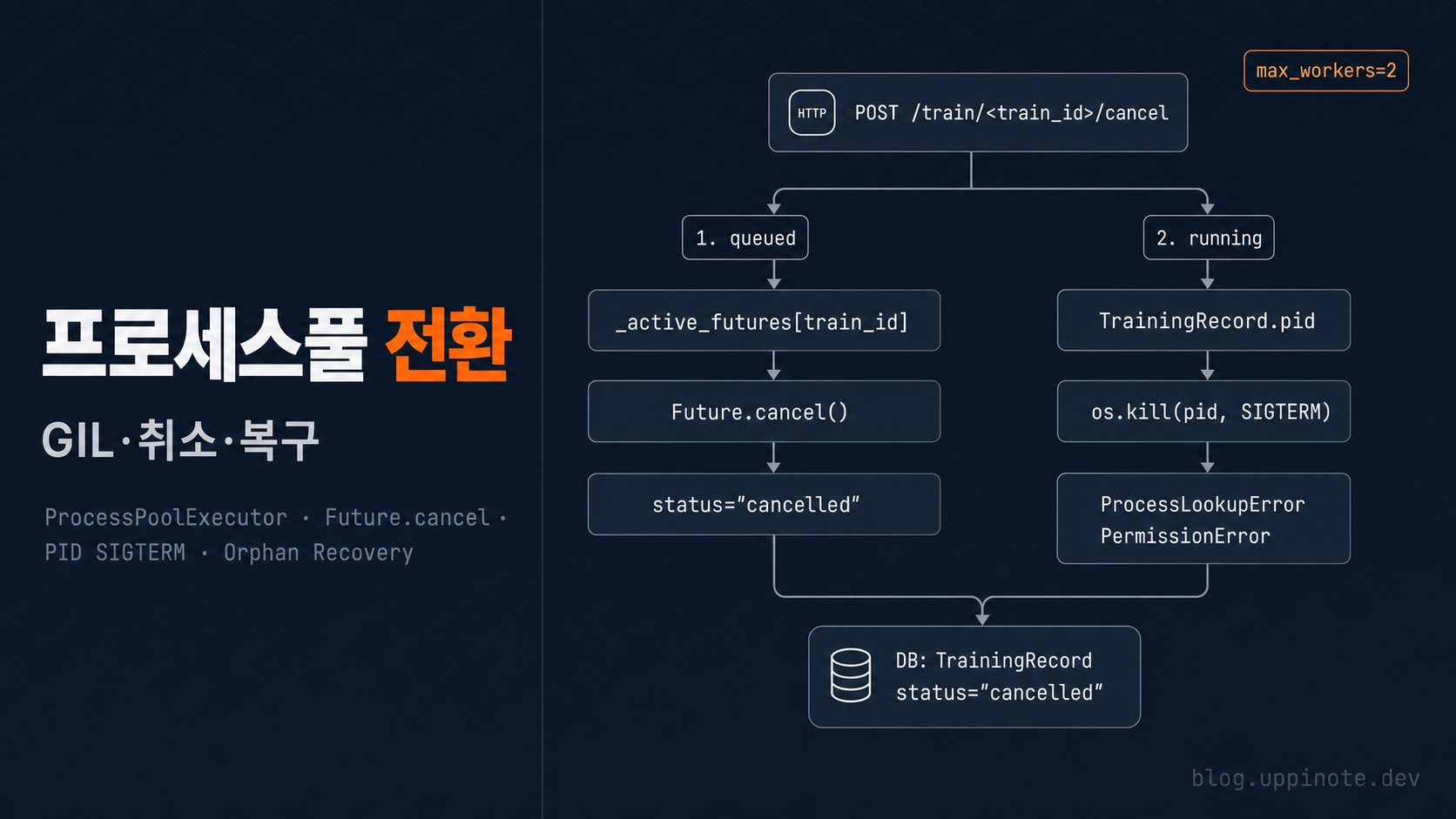
4. 취소: Future.cancel → PID SIGTERM 폴백
취소는 두 단계로 작동합니다.
1단계: 풀에 큐잉만 된 경우 → Future.cancel()
def cancel_training(uid, train_id):
future = _active_futures.get(train_id)
if future and future.cancel():
# 아직 실행 전이라 깔끔하게 취소됨
_active_futures.pop(train_id, None)
_mark_cancelled_in_db(train_id)
return "cancelled"
# ...
Future.cancel()은 작업이 아직 실행되지 않은 경우에만 성공합니다. max_workers=2인데 이미 2건이 돌고 있고 세 번째가 대기 중이면, 대기 중 작업은 이 방법으로 깔끔하게 취소됩니다.
2단계: 이미 실행 중인 경우 → PID 기반 SIGTERM
이미 워커 프로세스에서 학습이 실행 중이라면 Future.cancel()은 실패합니다. 파이썬 표준 라이브러리는 이 상태의 강제 종료를 지원하지 않습니다. 그래서 PID를 DB에 저장해 두고, 필요할 때 os.kill(pid, SIGTERM) 을 쏘는 폴백을 추가했습니다.
import os
import signal
def cancel_training(uid, train_id):
# 1단계: Future.cancel() 시도
future = _active_futures.get(train_id)
if future and future.cancel():
_mark_cancelled_in_db(train_id)
return "cancelled"
# 2단계: 이미 실행 중이면 PID로 강제 종료
app = _get_app()
with app.app_context():
rec = db.session.get(TrainingRecord, train_id)
if rec and rec.pid:
try:
os.kill(rec.pid, signal.SIGTERM)
except (ProcessLookupError, PermissionError):
pass # 이미 죽었거나 권한 없음 — 무시하고 DB 상태만 갱신
if rec:
rec.status = "cancelled"
rec.finished_at = datetime.now(timezone.utc)
db.session.commit()
return "cancelled"
워커 프로세스가 시작되면 run_yolo_train() 내부에서 os.getpid()를 DB에 저장해 두기 때문에, 부모 프로세스(Flask)는 이 PID를 읽어 시그널을 보낼 수 있습니다. SIGTERM은 SIGKILL보다 온건해서, Ultralytics YOLO가 내부 cleanup을 마친 뒤 종료할 기회를 줍니다.
예외 처리의 이유
try:
os.kill(rec.pid, signal.SIGTERM)
except (ProcessLookupError, PermissionError):
pass
ProcessLookupError: 이미 죽은 프로세스. 정상적으로 끝났는데 DB 업데이트만 늦은 경우입니다.PermissionError: 컨테이너/권한 경계를 넘은 경우. 드물지만 방어가 필요합니다.
이 두 경우는 "취소 실패"가 아니라 "이미 취소된 것과 동등한 상태"로 취급하고 DB 상태만 맞춰줍니다.
5. 취소 엔드포인트
라우트 레이어에서 취소 API를 추가했습니다.
# routes/training.py
from pathlib import Path
from services.training_service import cancel_training
from utils.auth_decorators import require_login
@bp.route("/train/<train_id>/cancel", methods=["POST"])
@require_login
def api_train_cancel(train_id):
uid = session["user_id"]
train_id = Path(train_id).name # ← path traversal 방지
status = cancel_training(uid, train_id)
return jsonify({"ok": True, "status": status})
Path(train_id).name은 URL 파라미터에서 경로 분리자와 상위 이동(..)을 모두 제거하는 Python 표준 관용구입니다. ../../etc/passwd 같은 입력이 오면 passwd만 남습니다. 이 한 줄로 path traversal 공격을 차단합니다.
6. Orphan 복구: 서버 시작 시 running 기록 정리
취소 기능을 만들고 나서도 한 가지 시나리오가 남았습니다. 서버가 죽는 도중 학습이 돌고 있었다면? DB에는 status="running"인 기록이 남지만, 실제 프로세스는 사라졌습니다. 다음에 서버를 다시 띄웠을 때 이 기록은 영원히 "running" 상태로 보입니다.
해결은 서버 기동 시 "고아가 된 running 기록을 찾아서 정리하는 함수"를 한 번 호출하는 것입니다.
# services/training_service.py
def recover_orphaned_training():
"""Mark orphaned 'running' training records as 'error'. Call on app startup."""
orphaned = TrainingRecord.query.filter_by(status="running").all()
for rec in orphaned:
if rec.pid:
try:
os.kill(rec.pid, 0) # 신호 0은 "프로세스 존재 확인"만 수행
continue # 살아있다면 건드리지 않음
except (ProcessLookupError, PermissionError):
pass # 죽었거나 권한 없음 → 고아
rec.status = "error"
logger.warning(f"[RECOVERY] Orphaned training {rec.id} marked as error")
db.session.commit()
if orphaned:
logger.info(f"[RECOVERY] Checked {len(orphaned)} orphaned training records")
os.kill(pid, 0)의 숨은 기능
os.kill(pid, 0)에서 시그널 번호 0은 실제로 아무 시그널도 보내지 않습니다. 대신 "해당 PID로 시그널을 보낼 수 있는가"만 체크합니다. 프로세스가 죽어 있으면 ProcessLookupError가 발생합니다. 살아 있는 프로세스를 건드리지 않고 생존 여부만 확인하는 표준 관용구입니다.
이 덕분에 "서버가 재시작되는 동안에도 별도 프로세스로 학습이 계속 돌고 있었을 가능성"을 배려할 수 있습니다. 정말 살아 있는 워커는 복구 대상에서 제외됩니다.
7. create_app()에 복구 훅 연결
recover_orphaned_training()은 서버가 기동할 때 한 번만 실행돼야 합니다. 지난 편에서 만든 create_app() 팩토리 안에 끼워 넣었습니다.
# app.py
def create_app():
app = Flask(...)
app.config.from_object(Config)
app.config["ALLOWED_ORIGINS"] = ALLOWED_ORIGINS
init_extensions(app)
app.before_request(csrf_protect)
register_blueprints(app)
# ⭐ Recover orphaned training records on startup
if app.config.get("SQLALCHEMY_DATABASE_URI"):
try:
with app.app_context():
from services.training_service import recover_orphaned_training
recover_orphaned_training()
except Exception as e:
logger.warning(f"Training recovery skipped (DB unavailable): {e}")
# SPA fallback ...
return app
세 가지 포인트가 있습니다.
- DB가 없으면 생략: CI/테스트 환경에서 DB 연결 없이
create_app()을 호출할 수 있도록SQLALCHEMY_DATABASE_URI유무를 확인합니다. - try/except로 graceful skip: DB가 설정돼 있지만 실제로 기동 시점에 연결할 수 없는 경우(PG가 아직 안 뜬 경우)에도 앱은 계속 뜨도록 합니다. 로그 경고만 남깁니다.
- 지연 import:
from services.training_service import recover_orphaned_training을 함수 내부에서 import 합니다. 모듈 로드 시점의 순환 의존을 피하기 위한 지난 편에서 설명한 패턴의 연장입니다.
8. 백그라운드 프로세스에서 Flask app context 얻기
가장 까다로운 문제가 남았습니다. run_yolo_train은 이제 완전히 분리된 프로세스에서 실행됩니다. 이 프로세스는 부모의 current_app을 볼 수 없습니다. Flask-SQLAlchemy 3.x는 db.app 속성도 제거했기 때문에, 전역 참조로 앱을 얻을 수도 없습니다.
해결책은 프로세스 단위로 create_app()을 한 번 호출해 캐싱 하는 것입니다.
def _get_app():
"""백그라운드 프로세스에서 사용할 Flask app 참조.
Flask-SQLAlchemy 3.x에서는 db.app이 없으므로,
create_app()을 한 번만 호출해 모듈 레벨에 캐시.
"""
if not hasattr(_get_app, "_cached"):
from app import create_app
_get_app._cached = create_app()
return _get_app._cached
함수 속성(_get_app._cached)에 싱글톤을 저장하는 전통적 관용구입니다. 프로세스 단위이므로 워커 프로세스마다 한 번씩 앱이 구성되지만, 같은 프로세스 안에서는 재사용 됩니다.
그리고 DB 작업은 반드시 with app.app_context():로 감쌉니다.
def run_yolo_train(uid, train_id, labeled_imgs, model_name, epochs, batch, img_size):
"""워커 프로세스에서 실행되는 실제 YOLO 학습 함수"""
from ultralytics import YOLO
import torch
app = _get_app()
with app.app_context():
# DB 상태 갱신: running + PID 저장
rec = db.session.get(TrainingRecord, train_id)
if rec:
rec.pid = os.getpid() # ← 취소용 PID 저장
db.session.commit()
# ... 실제 YOLO 학습 (GPU 사용, 수 분 ~ 수 시간)
with app.app_context():
# DB 상태 갱신: success / error
rec = db.session.get(TrainingRecord, train_id)
if rec:
rec.status = "success"
rec.finished_at = datetime.now(timezone.utc)
rec.map50 = final_metrics["mAP50"]
# ... 기타 메트릭
db.session.commit()
학습 시작 직후 os.getpid()를 DB에 저장해 두는 점이 핵심입니다. 이 PID가 앞서 본 cancel_training()의 2단계 SIGTERM 경로에서 사용됩니다.
9. SSE 진행 스트리밍에 "cancelled" 상태 추가
SSE(Server-Sent Events)로 프론트엔드에 학습 진행률을 스트리밍하는 기존 코드가 있었습니다. 종료 상태 체크 부분에 "cancelled"를 추가했습니다.
# routes/training.py (SSE generator 내부)
history = get_train_history(uid)
rec = next((h for h in history if h["id"] == train_id), None)
if rec and rec.get("status") in ["success", "error", "cancelled"]: # ← cancelled 추가
final_data = {
"epoch": last_sent_epoch,
"map50": rec.get("map50", 0),
"precision": rec.get("precision", 0),
"recall": rec.get("recall", 0),
"done": True,
"status": rec.get("status"), # ← 실제 상태 전달
}
yield f"data: {json.dumps(final_data)}\n\n"
break
두 가지 변경입니다.
- 종료 조건에
"cancelled"를 추가해 SSE 루프가 탈출하도록 했습니다. "done": True와 함께"status"를 전달해, 프론트엔드가 "완료/에러/취소"를 구분할 수 있도록 했습니다.
부수적으로 SSE에 2시간 타임아웃도 추가했습니다(이후 편에서 Fail-fast CORS와 함께 다룰 예정). 무한 루프를 방지하는 방어입니다.
10. 변경 요약
이번 커밋의 diff는 의외로 작았습니다.
app.py | 9 +++++
routes/training.py | 24 ++++++++-----
services/training_service.py | 82 +++++++++++++++++++++++++++++++++++++++++++-
3 files changed, 105 insertions(+), 10 deletions(-)
app.py: 복구 훅 한 블록routes/training.py:/cancel엔드포인트와 SSE 상태 추가services/training_service.py: 풀 생성, submit/cancel/recover 구현
3개 파일만 건드렸지만 구조적으로는 동시성 정책, 취소 정책, 복구 정책 세 가지가 동시에 바뀌었습니다.
11. 핵심 개념 정리
| 개념 | 이 프로젝트에서의 역할 |
|---|---|
ProcessPoolExecutor |
GIL 우회 + 동시 워커 수 제한(max_workers=2) |
Future.add_done_callback |
작업 완료 시 _active_futures 자동 정리 |
Future.cancel() |
큐잉만 된 작업의 안전한 취소 |
PID 기반 SIGTERM |
이미 실행 중인 프로세스를 종료하는 폴백 |
os.kill(pid, 0) |
시그널 없이 "프로세스 생존 확인"만 수행 |
| Orphan 복구 | 서버 재시작 후 "running" 잔여 기록 → "error" 전환 |
_get_app() 캐시 |
워커 프로세스 단위로 create_app()을 한 번만 호출 |
SSE cancelled 상태 |
종료 조건 확장, 프론트엔드 UX 구분 |
12. 베스트 프랙티스 체크리스트
- [ ] CPU를 쓰는 백그라운드 작업을
threading.Thread로 돌리고 있지 않나요? - [ ] 풀 워커 수를 실제 리소스 한계와 맞춰 설정했나요?
- [ ] 풀에 Future를 제출한 뒤 train_id로 추적할 수 있는 매핑을 두었나요?
- [ ]
Future.cancel()실패 시 PID 기반SIGTERM폴백이 있나요? - [ ] 워커 프로세스가 자신의 PID를 DB에 저장하나요?
- [ ] 서버 기동 시
recover_orphaned_training()같은 복구 훅이 호출되나요? - [ ]
os.kill(pid, 0)로 생존 확인 후에만 orphan으로 표시하나요? - [ ] 워커 프로세스에서
create_app()을 한 번만 호출해 캐싱하나요? - [ ] DB 작업이 모두
with app.app_context():로 감싸져 있나요? - [ ] SSE 종료 조건에 "cancelled" 상태가 포함돼 있나요?
13. FAQ
Q1. 왜 Celery나 RQ를 쓰지 않았나요?
A. 폐쇄망 배포가 전제였습니다. Redis 브로커나 별도 워커 프로세스 매니저를 도입하면 운영 복잡도가 올라갑니다. ProcessPoolExecutor는 표준 라이브러리이고, 추가 인프라가 필요 없습니다. 규모가 커져 학습이 분단위에서 시간단위로 길어지고, 여러 호스트로 분산이 필요해지면 그때 Celery로 마이그레이션할 계획입니다.
Q2. max_workers=2는 어떻게 정했나요?
A. GPU가 한 장이라면 1이 이론적 한계지만, Ultralytics가 내부적으로 CPU 전처리도 병행하기 때문에 GPU 한 장 + CPU 전처리 한 건이 겹쳐도 전체 스루풋은 떨어지지 않았습니다. 그래서 2로 설정했습니다. 사용자 요청이 몰릴 때는 세 번째가 자연스럽게 큐잉되며, 프론트엔드에는 "대기 중"으로 표시합니다.
Q3. 왜 SIGKILL이 아닌 SIGTERM인가요?
A. SIGKILL은 프로세스 종료 전 cleanup을 허용하지 않습니다. Ultralytics YOLO는 중간 체크포인트 저장이나 파일 핸들 닫기 같은 종료 처리를 내부적으로 수행하는데, SIGKILL을 받으면 이런 것들이 모두 건너뛰어집니다. SIGTERM을 보내고, 몇 초 후에도 살아 있으면 SIGKILL로 escalate 하는 것이 더 안전합니다. 이 프로젝트는 현재 SIGTERM만 사용하지만, 확장이 필요하면 escalate 단계를 추가할 수 있습니다.
Q4. _get_app()을 함수 속성으로 캐싱하는 게 이상합니다. 왜 전역 변수가 아닌가요?
A. 순수 기능적으론 동일합니다. 함수 속성을 쓰면 스코프가 함수 이름 하나에 집중되고, 모듈의 전역 네임스페이스를 오염시키지 않습니다. 모듈 상단의 전역 변수는 "이 모듈이 사용하는 상태"를 구독할 때 읽어야 할 영역이 넓어지지만, 함수 속성은 "그 함수만 아는 정적 변수" 개념에 가깝습니다. 마찬가지 이유로 C 언어의 static 지역 변수 패턴과 유사한 용도입니다.
Q5. 서버 기동 시 복구 훅이 실수로 진짜 살아 있는 학습까지 "error"로 표시하지 않나요?
A. os.kill(pid, 0) 체크가 정확히 그걸 방어합니다. 살아 있는 프로세스는 시그널 0을 받아도 ProcessLookupError를 발생시키지 않으므로, 복구 로직이 continue로 건너뜁니다. 다만 이 방어는 같은 호스트에서만 작동합니다. 다중 호스트 배포가 되면 PID만으로 판단할 수 없으니, hostname도 함께 저장해야 합니다. 현재 아키텍처 기준에서는 충분합니다.
Q6. submit()에 큰 인자(labeled_imgs)를 넘기는 건 직렬화 부하가 크지 않나요?
A. 좋은 지적입니다. ProcessPoolExecutor는 작업 함수와 인자를 직렬화해 워커에 전달합니다. labeled_imgs가 수천 개를 넘어가면 직렬화 비용이 무시할 수 없어집니다. 이 프로젝트는 현재 수백 장 규모라 문제없지만, 스케일이 커지면 "train_id만 전달하고 워커가 DB에서 다시 조회하는" 방식으로 바꿀 수 있습니다. 지금은 명시적 인자가 테스트/디버깅에 편해 유지하고 있습니다.
14. 참고 자료
- Python 공식 문서 (
concurrent.futures): 검색 키워드python concurrent futures ProcessPoolExecutor - Python 공식 문서 (
signal): 검색 키워드python signal module os.kill - Flask-SQLAlchemy 3.x 공식 문서 (app context): 검색 키워드
flask-sqlalchemy application context - Ultralytics YOLO 학습 API: 검색 키워드
ultralytics yolo train python api
15. 다음 단계
세 편에 걸쳐 Flask 앱의 구조 / 데이터 / 실행 모델을 리팩토링했습니다. 이제 코드 리뷰를 돌려 보니 예상치 못한 문제가 발견됐습니다. 서비스 레이어에 N+1 쿼리가 세 곳이나 숨어 있었던 것입니다. 루프 안에서 관계 속성(image.annotations)을 건드리면서 사용자 100명의 이미지 수를 세는 데 DB 라운드트립이 101회 발생하고 있었습니다. 다음 편에서는 이 N+1 세 곳을 어떻게 찾고, 어떤 패턴으로 고쳤는지 다룹니다. (Prisma/TypeScript 편 독자분들께는 친숙한 이야기지만, Python/SQLAlchemy 현장의 실전 예시로 다시 풀어 보겠습니다.)
🐍 Flask 백엔드 실전 시리즈 (9부작)
- 모놀리식 app.py를 Blueprint로 분해하기
- JSON 파일 DB에서 PostgreSQL로 마이그레이션
- ML 학습 백그라운드 실행: ProcessPoolExecutor (현재 글)
- Python/SQLAlchemy N+1 쿼리 잡기
- train과 val이 같은 폴더일 때의 조용한 ML 버그
- 하나의 백엔드로 Detection/Classification/Segmentation
- Fail-fast 설정 검증과 Path Traversal 방어
- Rate Limiting을 걷어낸 날: 폐쇄망 보안
- 작지만 기억할 만한 네 가지 교훈