메모 한 통에 10MB? API 입력 길이 제한으로 무제한 텍스트 남용 막기
리포트 메모 필드에 아무 제한 없이 문자열을 받고 있었다. 악의든 실수든 누군가 MB 단위 텍스트를 넣으면 DB와 네트워크가 먼저 비명을 지른다. 5분이면 추가할 수 있는 방어선을 PR 리뷰에서 발견한 기록.

1. 문제 상황
1.1 리뷰어의 한 줄 지적
주간 리포트 PR에서 메모 편집 API를 만든 직후, 리뷰에서 이런 코멘트가 달렸습니다.
메모/코멘트 필드에 길이 제한이 없습니다. 누군가 MB 단위 문자열을 보내면?
당시 PATCH 핸들러는 길이 검증 없이 통과했습니다:
// ❌ Before: 길이 검증 없음
const ALLOWED = ["progressStatus", "highlights", "nextWeekPlan"] as const;
export async function PATCH(request, { params }) {
const { entryId } = await params;
const body = await parseBody(request);
const data = pickAllowedFields(body, ALLOWED);
const updated = await prisma.reportEntry.update({
where: { id: entryId },
data,
});
return NextResponse.json(updated);
}
이 핸들러는 progressStatus: "...10MB의 문자열..."를 받으면 그대로 DB에 저장합니다. Prisma와 PostgreSQL은 각자 자기 한계치를 가지고 있지만(text 타입은 사실상 무제한), 애플리케이션 레벨에서 아무 방어가 없다는 게 문제였습니다.
1.2 구체적인 위험
길이 제한이 없는 입력의 위험:
- DB 팽창: 한 레코드가 수 MB가 되면 인덱스가 느려지고 VACUUM 부담이 커집니다.
- 네트워크 대역폭: 리포트 조회 API가 이 레코드를 읽어오면 응답이 수 MB 단위로 부풀어오릅니다.
- 프론트엔드 렌더링 지연: 10MB 마크다운을 브라우저에서 파싱하려면 수 초가 걸립니다.
- 메모리 피크: Next.js API route가 body를 파싱하며 메모리를 일시 점유.
- 악의적 남용: rate limit를 우회해 DB 용량을 빠르게 소진시키는 벡터.
1.3 "나는 그럴 리 없어"가 안 먹히는 이유
"우리 사내 툴이니까 사용자가 악의적으로 남용하지 않겠지"라는 가정은 위험합니다.
- 실수: 클립보드에 긴 텍스트가 있는 상태에서 Cmd+V 한 번으로 입력.
- 스크립트 버그: 자동화 스크립트가 변수 치환 실수로 JSON 전체를 붙여넣음.
- 브라우저 확장: 자동 저장 확장 기능이 비정상 상태에서 긴 텍스트를 주입.
- 실제 악의: 내부자도 악의적일 수 있음. 또는 탈취된 세션.
"사용자가 합리적이라고 가정"하는 API는 거의 항상 언젠가 뚫립니다. 검증은 무료에 가까우니 걸어두는 게 합리적입니다.
2. 해결 방법
2.1 두 단계 검증
필요한 검증은 두 가지입니다:
- 타입 검증: 문자열이 맞는지
- 길이 검증: 설정된 최댓값 이하인지
두 단계 모두 실패하면 400 ValidationError로 응답합니다.
2.2 구현
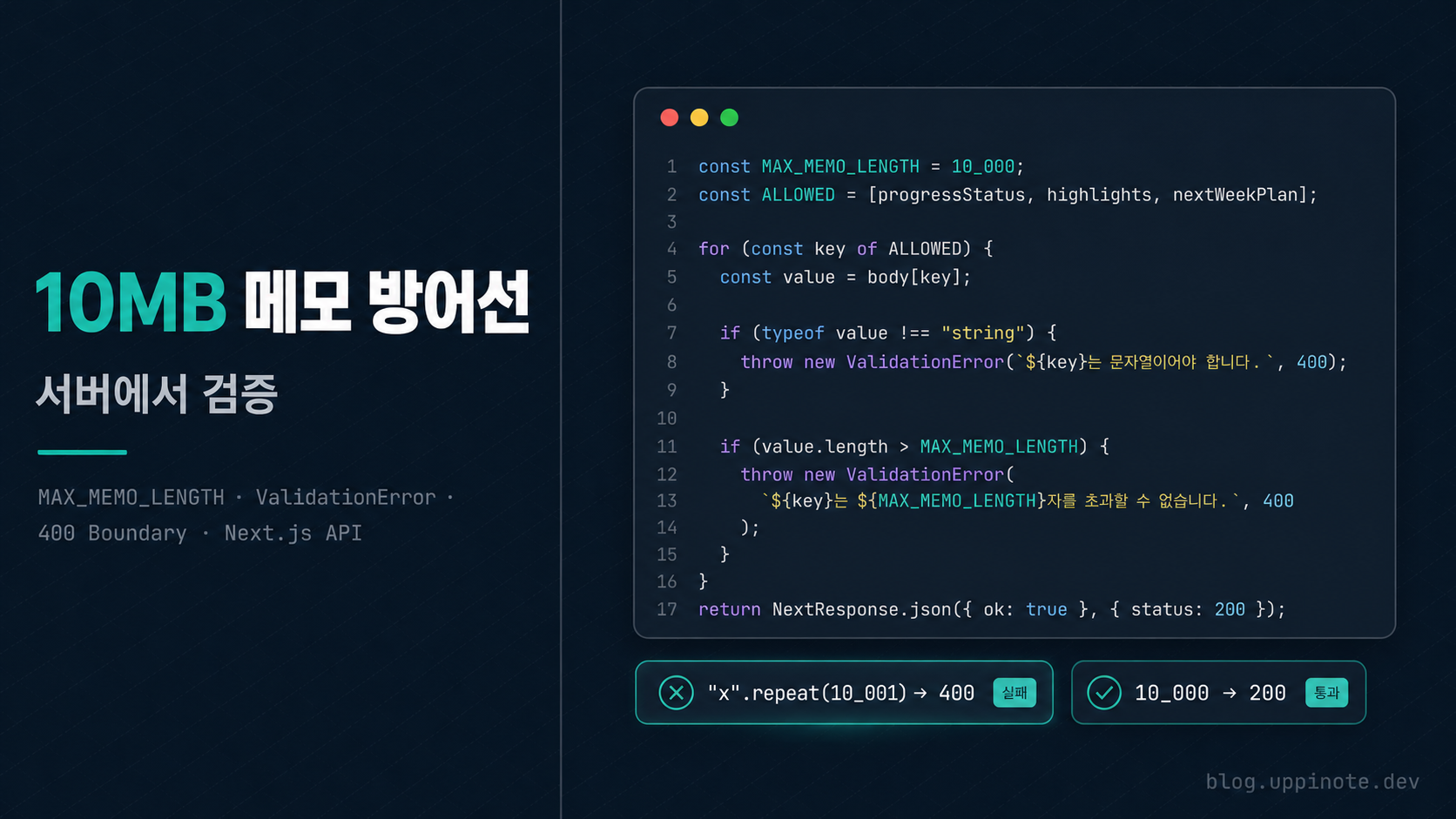
// ✅ After: 타입 + 길이 검증 추가
import { parseBody, pickAllowedFields, handleApiError, ValidationError } from "@/lib/api-utils";
const ALLOWED = ["progressStatus", "highlights", "nextWeekPlan"] as const;
const MAX_MEMO_LENGTH = 10_000;
export async function PATCH(request: Request, { params }: { params: Promise<{ entryId: string }> }) {
const { entryId } = await params;
try {
await requireAuth();
await requireReportEntryPermission(entryId, "edit");
const body = await parseBody(request);
const data = pickAllowedFields(body, ALLOWED);
// 각 메모 필드의 길이 제한 — 과도한 크기 방지 (DB/네트워크 남용 차단)
for (const field of ALLOWED) {
const value = data[field];
if (value !== undefined) {
if (typeof value !== "string") {
throw new ValidationError(`${field} must be a string`);
}
if (value.length > MAX_MEMO_LENGTH) {
throw new ValidationError(`${field} exceeds ${MAX_MEMO_LENGTH} characters`);
}
}
}
const updated = await prisma.reportEntry.update({
where: { id: entryId },
data,
});
return NextResponse.json(updated);
} catch (error) {
return handleApiError(error, "PATCH /api/reports/weekly/entries/[entryId]");
}
}
2.3 상수와 적용 범위
필드마다 다른 한도를 두는 것도 가능합니다:
| 필드 | 한도 | 이유 |
|---|---|---|
progressStatus, highlights, nextWeekPlan |
10,000자 | 마크다운 메모. 한 사람이 손으로 쓸 수 있는 상한 |
comment.content |
5,000자 | 한 코멘트는 메모보다 짧아야 함 |
project name |
200자 | 제목은 짧게 |
project definition |
50,000자 | 긴 프로젝트 설명 문서 수준 허용 |
"10,000자"라는 숫자는 임의이지만, 대략 한국어 3,000~4,000단어 정도로 실질적으로 한 번에 쓸 수 있는 최댓값입니다. 더 긴 텍스트는 Notion 같은 외부 도구를 쓰는 게 자연스럽습니다.
3. 테스트
3.1 400 응답 테스트
describe("PATCH /api/reports/weekly/entries/[entryId]", () => {
it("메모가 10,000자 초과면 400", async () => {
const body = { highlights: "x".repeat(10_001) };
const req = new Request("http://localhost/api/reports/weekly/entries/e1", {
method: "PATCH",
body: JSON.stringify(body),
});
const res = await PATCH(req, { params: Promise.resolve({ entryId: "e1" }) });
expect(res.status).toBe(400);
const json = await res.json();
expect(json.error).toMatch(/exceeds 10000 characters/);
});
it("메모가 10,000자 이하면 성공", async () => {
const body = { highlights: "x".repeat(10_000) };
// ... expect 200
});
it("문자열이 아니면 400", async () => {
const body = { highlights: 123 };
// ... expect 400
});
});
세 케이스로 경계(정확히 최댓값), 초과, 타입 오류를 모두 커버합니다.
3.2 테스트에서 repeat의 비용
"x".repeat(10_001)은 메모리 상에 10KB 문자열을 즉시 생성합니다. 실제 테스트 시 문제가 되지 않지만, 만약 100만 글자 테스트라면 파일 I/O가 아닌 메모리에서 처리해야 해서 조심스럽습니다. 10KB는 무시할 수 있는 수준.
4. 핵심 개념 정리
4.1 "Depth of Validation" 원칙
입력 검증은 여러 층으로 쌓입니다. 방어선 하나가 뚫려도 다음이 막아주는 구조가 중요합니다.
| 층 | 예시 | 이번 글 |
|---|---|---|
| 클라이언트 | HTML maxLength 속성 |
✗ (별도 작업) |
| 네트워크 edge | Nginx client_max_body_size |
✗ (인프라 레벨) |
| 프레임워크 | Next.js body size limit | ⚠️ (기본 4MB) |
| 애플리케이션 | Zod/Valibot 스키마 또는 수동 검증 | ✅ 이 글 |
| DB | VARCHAR(N) 제약 |
✗ (Prisma String은 무제한) |
이 글은 애플리케이션 레벨의 방어선을 추가하는 이야기입니다. 클라이언트/네트워크 레이어의 방어선도 같이 강화하는 게 이상적이지만, 애플리케이션 레벨은 가장 저렴하고 가장 확실합니다.
4.2 왜 Zod/Valibot 같은 스키마 라이브러리를 쓰지 않았나?
선택지는 두 가지였습니다:
A. 수동 검증 (이 글의 선택)
for (const field of ALLOWED) {
if (typeof value !== "string") throw new ValidationError(...);
if (value.length > MAX_MEMO_LENGTH) throw new ValidationError(...);
}
B. Zod 스키마
const MemoSchema = z.object({
progressStatus: z.string().max(10_000).optional(),
highlights: z.string().max(10_000).optional(),
nextWeekPlan: z.string().max(10_000).optional(),
});
const data = MemoSchema.parse(body);
이 프로젝트는 이미 수동 검증 헬퍼(pickAllowedFields, ValidationError)를 가지고 있었고, 스키마 라이브러리를 새로 도입하는 것이 오버헤드였습니다. 다른 핸들러들도 수동 검증 스타일이라 일관성을 유지하는 게 우선이었고요.
신규 프로젝트라면 처음부터 Zod를 쓰는 게 낫습니다:
- 타입 추론으로
data타입 자동 생성 - 중첩 객체/배열 검증 간편
- 런타임 + 컴파일타임 타입 일치
4.3 ValidationError의 역할
이 프로젝트에는 ValidationError라는 커스텀 에러 클래스가 있습니다:
// src/lib/api-utils.ts
export class ValidationError extends Error {
constructor(message: string) {
super(message);
this.name = "ValidationError";
}
}
export function handleApiError(error: unknown, context: string) {
if (error instanceof ValidationError) {
return NextResponse.json({ error: error.message }, { status: 400 });
}
// ... 다른 에러 처리
}
핸들러에서 throw new ValidationError(...)만 하면 handleApiError가 자동으로 400 응답을 만듭니다. 이 패턴 덕분에 "검증 실패 → 에러 메시지 → 400 응답"의 보일러플레이트가 사라졌습니다.
관련 글: API 에러 처리 표준화: withErrorHandler 패턴으로 중앙집중화하기.
5. 확장: 다른 방어선
5.1 Next.js body size limit
Next.js API route는 기본적으로 4MB의 body 크기 제한을 가집니다. 이를 넘으면 자동으로 413 Payload Too Large를 반환합니다. 하지만 이것만으로는 부족한 이유:
- 4MB는 메모 하나로는 너무 커서 악의적 남용에 가까운 수준까지 허용
- 여러 필드가 동시에 3MB씩 들어있으면 여전히 4MB 미만이라 통과
- 응답 측 대역폭 문제는 막지 못함
애플리케이션 레벨 검증이 더 좁은 제한을 걸어주는 게 현실적입니다.
5.2 DB 레벨 제약 (사용하지 않았지만 고려)
PostgreSQL에서는 VARCHAR(N) 제약으로 DB 레벨에서 길이를 막을 수 있습니다:
ALTER TABLE "ReportEntry"
ALTER COLUMN "highlights" TYPE VARCHAR(10000);
장점: 애플리케이션 우회 공격(raw SQL 주입 등)에도 방어가 유지됨.
단점: Prisma 스키마와 동기화 필요, 한도 변경 시 migration 부담.
이 프로젝트는 Prisma의 String 타입(TEXT에 매핑)을 쓰고 있어 DB 제약을 따로 걸지는 않았습니다. 변경 유연성이 더 중요한 단계라서.
5.3 Rate limiting
길이 제한과 호출 빈도 제한은 별개입니다. 둘 다 필요합니다:
- 길이 제한: "한 번에 너무 큰 요청 금지"
- Rate limit: "짧은 시간에 너무 많은 요청 금지"
관련 글: Next.js API에 Rate Limiting 구현하기 (메모리 기반).
6. 베스트 프랙티스
6.1 체크리스트
- [ ] 모든 문자열 입력 필드에
max length설정 — 기본값은 100~10,000 사이 - [ ] 타입 검증도 함께 (
typeof value !== "string") - [ ] 에러 메시지에 어느 필드가 얼마나 초과했는지 명시
- [ ] 경계값 테스트 3가지:
N-1자(통과),N자(통과),N+1자(실패) - [ ] 클라이언트에도 같은 한도 적용 (
textarea maxLength) - [ ] 한도는 상수로 추출해 클라/서버 공유
6.2 상수 공유 패턴
// src/lib/limits.ts
export const MEMO_MAX_LENGTH = 10_000;
export const COMMENT_MAX_LENGTH = 5_000;
// 서버
if (value.length > MEMO_MAX_LENGTH) throw new ValidationError(...);
// 클라이언트
<textarea maxLength={MEMO_MAX_LENGTH} />
클라이언트와 서버가 같은 상수를 import하면 한도 변경 시 한 곳만 수정하면 됩니다. 이 프로젝트는 같은 src 트리 안이라 import가 간단했습니다.
6.3 에러 메시지의 정보량
// ❌ 너무 적음
throw new ValidationError("Invalid input");
// ❌ 너무 많음 (해커에게 힌트)
throw new ValidationError(`${field} exceeded max length of 10000 at position ${value.length}`);
// ✅ 적당함
throw new ValidationError(`${field} exceeds ${MAX_MEMO_LENGTH} characters`);
필드 이름과 한도를 명시해 사용자가 문제를 알 수 있게 하되, 내부 구현을 노출하지 않습니다.
7. FAQ
Q. 왜 10,000자인가요?
A. 경험적 결정입니다. 한국어 텍스트에서 10,000자는 대략 A4 5페이지 분량입니다. 한 메모 필드가 이보다 길어지면 UX가 이미 망가졌다고 봐야 합니다. 프로덕트마다 적정값이 다르니 "자체 UI에서 손으로 쓸 수 있는 최댓값"을 기준으로 잡는 게 좋습니다.
Q. 바이트가 아닌 문자 수로 재는 이유는?
A. UTF-8에서 한국어 문자 1개는 3바이트를 차지하므로, 바이트 기준으로 하면 한국어 사용자가 영어 사용자보다 더 적은 "글자"를 쓸 수 있게 됩니다. JavaScript의 string.length는 UTF-16 코드 유닛 수를 반환하므로 한글과 영어 모두 1로 셉니다 (이모지는 2 이상일 수 있음). 실용적 기준으로는 .length가 적절합니다.
Q. 이모지가 2글자로 세어지는 건 문제인가요?
A. 극단적으로 이모지로만 채운 10,000자는 정확히 5,000 이모지입니다. 악의적 남용이라면 이미 그 시점에서 비정상입니다. 엄밀히 "보이는 글자 수"를 세고 싶다면 [...string].length (Array.from(string).length)로 code point를 셀 수 있습니다. 현실에서는 .length가 충분합니다.
Q. 클라이언트에서만 제한하면 안 되나요?
A. 안 됩니다. 클라이언트 검증은 UX를 위한 것이고, 서버 검증은 보안을 위한 것입니다. 클라이언트는 DevTools, curl, 스크립트로 우회 가능하므로, 서버 검증이 없으면 모든 방어가 무력화됩니다.
Q. 기존 데이터에 이미 초과분이 있으면?
A. 신규 제한은 UPDATE 경로에만 적용되므로 기존 DB 값은 그대로 유지됩니다. 만약 기존 값도 축소하고 싶다면 마이그레이션 스크립트로 UPDATE ... WHERE LENGTH(...) > 10000 처리가 필요합니다. 이 프로젝트는 초기라 해당 없는 상황이었습니다.
Q. pickAllowedFields와 중복 검사 아닌가요?
A. pickAllowedFields(body, ALLOWED)는 허용된 키만 통과시키는 필터이고, 길이/타입 검증은 값 자체에 대한 검사입니다. 두 가지는 서로 다른 축이고, 함께 써야 완전합니다.
8. 참고 자료
- OWASP - Input Validation Cheat Sheet
- Next.js - API Routes size limit
- 관련 글: API 에러 처리 표준화: withErrorHandler 패턴으로 중앙집중화하기
- 관련 글: Next.js API에 Rate Limiting 구현하기 (메모리 기반)
9. 다음 단계
길이 검증을 쌓아두면 다음은 내용 검증입니다. 마크다운 메모라면 XSS 방지를 위한 sanitization, 금칙어 필터, 스팸 탐지가 이어질 수 있습니다. 각 단계마다 "정말 필요한가"를 물어야 하고, 과한 검증은 UX를 해칩니다. 이번 PR에서는 길이 제한까지만 추가하고 나머지는 문제가 생기면 그때 도입하기로 결정했습니다.